
Codepage zu Unicode: Präkognition
Während die Hexe oft zur Erstellung von Legacy-Dateien eingesetzt wird, ist sie ebenso geschickt darin, diese zu retten. Dieses Ritual beinhaltet das Umwandeln von altem, Codepage-kodiertem Text und dessen „Beförderung“ zu modernem Unicode (UTF-8), wodurch er mit heutigen Desktop-Editoren und Webstandards kompatibel wird.
1. Statistisches Scrying
Wenn eine Legacy-Datei in den Kessel geworfen wird, erscheint sie normalerweise mit einem blauen ![]() Symbol. Im Gegensatz zu Unicode-Dateien, die klare Kodierungssignaturen enthalten, bestehen Legacy-Dateien oft nur aus Rohdaten. Um sie zu identifizieren, führt die Hexe eine statistische Analyse des Textes durch, um seine wahrscheinliche Sprache und sein Gebietsschema (Locale) zu „erraten“.
Symbol. Im Gegensatz zu Unicode-Dateien, die klare Kodierungssignaturen enthalten, bestehen Legacy-Dateien oft nur aus Rohdaten. Um sie zu identifizieren, führt die Hexe eine statistische Analyse des Textes durch, um seine wahrscheinliche Sprache und sein Gebietsschema (Locale) zu „erraten“.
2. Die Wahrscheinlichkeits-Kreisdiagramme
Da die Hexe eine fundierte Vermutung anstellt, sieht das Verzauberungen-Fenster für blaue Dateien etwas anders aus. Sie werden Blau/Rote Kreisdiagramme 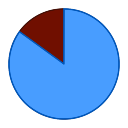 bemerken:
bemerken:
- Das blaue Segment: Gibt die statistische Wahrscheinlichkeit an, dass die Datei basierend auf bekannten linguistischen Mustern zu dieser spezifischen Codepage gehört.
- Das rote Segment: Zeigt die Wahrscheinlichkeit an, dass die Auswahl nicht übereinstimmt.
- Die Wahl: Wenn die Hexe sehr zuversichtlich ist, wird sie den wahrscheinlichsten Kandidaten vorauswählen, aber Sie sollten immer die Spiegel konsultieren, um dies zu überprüfen.
3. Der Spiegel der Beförderung
Der Unicode-Betrachter (der obere Spiegel) ist Ihr wichtigstes Werkzeug während dieses Rituals. Er zeigt Ihnen genau, wie der Text aussehen wird, sobald er zu UTF-8 befördert wurde.
- Wenn Sie im oberen Spiegel verstümmelten Text oder falsche Symbole sehen, hat die Hexe möglicherweise die falsche Ausgangs-Codepage ausgewählt.
- Versuchen Sie, verschiedene Verzauberungen in der Liste auszuwählen, bis der Unicode-Betrachter den Text so wiedergibt, wie er ursprünglich gelesen werden sollte.
4. Die Beförderung finalisieren
Sobald der Text im oberen Spiegel korrekt erscheint, klicken Sie auf das Exportieren  Symbol. Die Hexe wird den Text mit einem modernen UTF-8-Siegel versehen, um sicherzustellen, dass er von jeder modernen Anwendung gelesen werden kann, während die ursprünglichen Zeilenenden beibehalten werden.
Symbol. Die Hexe wird den Text mit einem modernen UTF-8-Siegel versehen, um sicherzustellen, dass er von jeder modernen Anwendung gelesen werden kann, während die ursprünglichen Zeilenenden beibehalten werden.
Hinweis: Wenn der Text nur Standard-7-Bit-Zeichen enthält, wird das Symbol Grau ![]() . Diese Dateien sind universell und erfordern kein komplexes Scrying für die Beförderung.
. Diese Dateien sind universell und erfordern kein komplexes Scrying für die Beförderung.